Ein Umfangreiches Programm installieren, ohne den eienen PC zu zerschiessen? Ein neues Betriebssystem einfach mal ausprobieren, ohne die Funktion des aktuellen Systems zu riskieren? Mehrere Dienste anbieten, die sich gegenseitig nicht beeinflussen?
Für diese und andere Zwecke ist Docker ein bewährtes Werkzeug geworden. Es gibt kaum noch einen Server-Dienst, den man nicht auch als Docker-Image haben kann, und zunehmend erobern Docker-Container auch den bereich der GUI-Anwendungen, oder sogar ganzer Windows-Installationen.
Etwas störend ist allenfalls, dass Docker mitsamt seinen Containern auf einem PC läuft, den man vcielleicht auch für anderes braucht, und dass jeder noch so kleine Dienst ein ganzes Betriebssystem “mitschleppt”.
Wenn man einen passenden Computer “übrig” hat (bei mir zum Beispiel ein ausrangierter Server, dem ich den laufenden Praxisbetrieb aus Altersgründen nicht mehr zutrauen mag), kann man dort einen “Hypervisor” installieren.
Das ist, wenn man das ganze mit dem Begriff verbundene Tech-Geschwurbel mal weglässt, einfach ein Betriebssystem, das darauf spezialisiert ist, virtuelle Maschinen zu verwalten.
Auf so einem Gerät kann man in weniger als einer Minute einen kompletten virtuellen PC installieren und starten, und ebenso schnell wieder löschen. Ein solcher virtueller PC lässt sich nicht von anderen Computern im LAN unterscheiden. Er ist je nach zugeordneten Hwrdware-Ressourcen ebenso leistungsfähig, wie irgendein anderer.
Für einen Hypervisor kann man viel Geld ausgeben, wenn man ihn zum Beispiel bei Broadcom lizensiert. Man kann aber auch einen OpenSource-Hypervisor auf Linux-BNasis erst mal kostenlos installieren und nutzen.
Proxmox Virtual Environment kommt mit einem sehr einfachen Installer, den man einfach auf CD oder USB-Stick schreiben und vorn dort aus booten kann.
Danach kann man mit dem Browser auf serveradresse:8006 navigieren und das System administrieren.
Proxmox kennt zwei verschiedene Arten von virtuellen Systemen:
Virtual Machines (VM):
Die sind vergleichbar mit Docker-Containern. Eine VM kann ein beliebiges Betrienbssystem enthalten, sofern es auf dem X86-Prozessor des Hosts ausführbar ist. Es braucht aber auch entsprechend Platz und Ressourcen. EIne VM erstellt man mit dem blauen Button “Create VM” rechts oben. Danach muss man einen Namen für die Maschine eingeben und dann ein Start-Image auswählen. Das kann entweder eine CD/DVD im physischen Laufwerk sein, oder eine ISO-Datei. Letztere muss man allerdings zuerst hochladen. Die Option dafür ist ein wenig versteckt: Gehen Sie in der Dropbox links oben auf “Folder view”, klappen Sie dann “Storage” auf. Wählen Sie das lokale Laufwerk und dort dann “ISO-Images”:
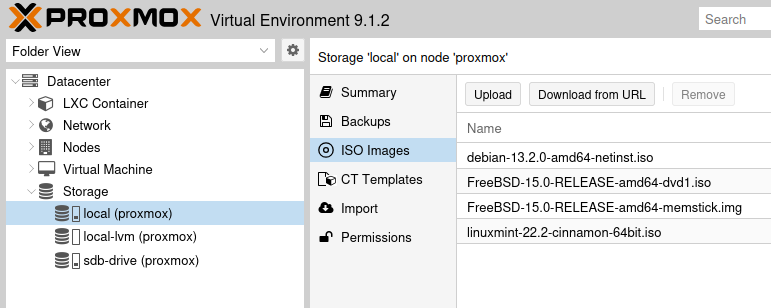
Wählen Sie “Upload”, wenn Sie eine entsprechende ISO-Datei schon auf Ihrem Computer haben, oder “Download from URL” um eine Adresse zum Herunterladen einzugeben.
Wenn Sie die passende ISO-Datei haben, können Sie diese dann beim Erstellen der VM eintragen:
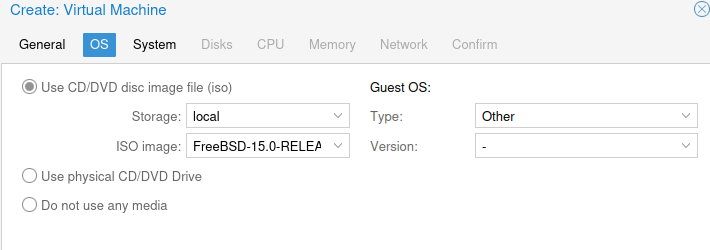
Bei den weiteren Otionen können Sie meist die Voreinstellung belassen. Wenn in der Auswahl vorgesehen, können Sie mit “virt…” Geräten eine etwas bessere Performance erreichen: Paravirtualisierte Hardware geift direkt auf die Geräte des Hosts zu, statt sie mittels Software zu emulieren, und gewinnt dadurch Leistung auf Kosten der dann nicht mehr so vollständigen Isolierung vom Hostsystem. Am Ende können Sie die Maschine starten und sich sofort mit der Konsole verbinden:
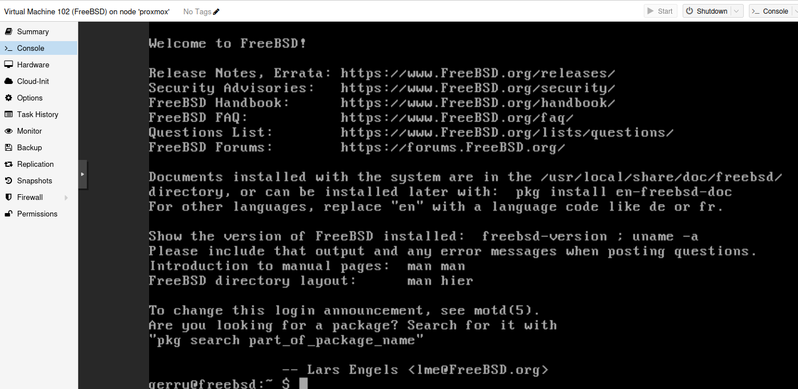
Von hier aus können Sie z.B. einen openssh-server installieren, um sich auch unabhöngig von Proxmox mit dieser virtuellen Maschine verbinden zu können, oder auch einen grafischen Deskop installieren, auf den Sie sich mit VNC, X2Go oder xrdp verbinden können (siehe weiter unten).
Linux Container (lxc)
Das sind “leichtgewichtige” Container. Diese bringen kein komplettes Betriebssystem mit, sondern nutzen das des Host-Systems. Darum kommen als lxc nur Linux-Varianten in Frage. Einen Container erstellen Sie mit dem blauen Button “Create CT” rechts oben. Als erstes müssen Sie mindestens einen Namen und ein Passwort für die Maschine eingeben. Anstelle eines ISO Images müssen Sie dann ein “Template” auswählen. Auch das müssen Sie dem System zunächst zur Verfügung stellen. Das geht in gleicher Weise, wie oben für ISO beschrieben:
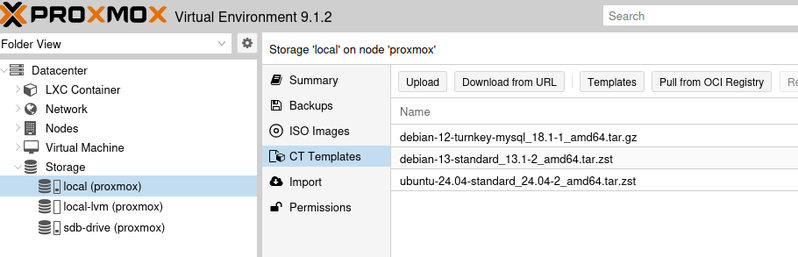
Ansonsten hat man hier nicht ganz soviele Einstellmöglichkeiten, wie für VMs. Immerhin kann man Diskgrösse, Speicherausstattung und Zahl der zugeordneten CPU-Kerne angeben. Danach startet die Maschine in wenigen Sekunden. Auch hier kann man die Ausstattung an der Konsole komplettieren, es gibt hier kaum Unterschiede zu den VMs.
Datensicherung
Proxmox Container haben einen grossen Vorteil gegenüber “echten” Computern und auch gegenüber Docker-Containern: Es ist kinderleicht, vom momentanen Zustand einer Maschine einen Snapshot zu erstellen, zu dem man jederzeit wieder zurück kann. Und ebenso leicht kann man ein komplettes Backup erstellen.
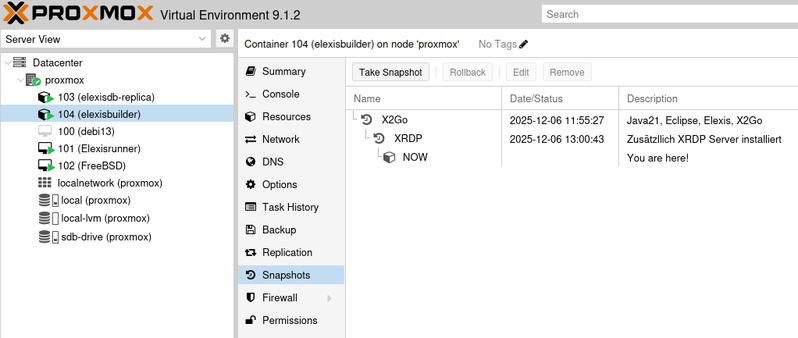
Also einfach immer, bevor man etwas “kritisches” in der VM installiert oder ändert, rasch einen Snapshot erstellen, was wenige Sekunden dauert, dann kann man wieder zurück, falls etwas schief gegangen ist.
Beispiel: Debian 13 mit einfachem XFCE Desktop
- CT mit debian13 (debian-13-standard_13.1-2_amd64.tar.zst template) erstellen und starten. Einloggen als root mit dem beim Erstellen vorgegebenen Passwort
- apt update && apt upgrade -y
- apt install sudo openssh-server xfce4 dbus-x11 xrdp
- adduser IhrUserName
- adduser IhrUserName sudo
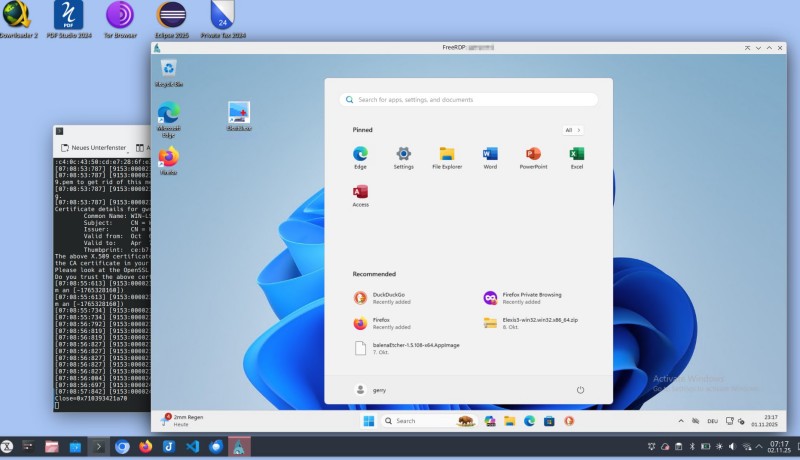
Danach können Sie von einem anderen Computer aus mit xfreerdp3 /v:adresse /u:IhrUserName /p:IhrPassword +dynamic-resolution auf diesen virtuellen debian 13-Computer mit xfce Desktop zugreifen. Wenn Sie einen Windows-PC benutzen, können Sie die Verbindung einfach mit mstsc (Windows Remoteverbindung) herstellen.
Eventuell müssen Sie das Tastaturlayout im client dann noch einmal einstellen, obwohl Sie es bei der Installation schon gemacht haben. Manchmal “vergisst” xrdp auch wieder das layout beim nächsten Login und man muss es mit setxkbmap ch wieder einstellen.